Data Science capstone projects batch #17
by Ekaterina Butyugina
In this blog post, we highlight the projects that our Data Science students Batch #17 completed during the last month of their three-month program. Take a look at the results they've achieved in such a short period of time.
Cortexia: Sustainable Clean City - Litter Detector
Students: Satanei Zhinova, Jeremy Choppe, Martin Erhardt
Cortexia is a technology firm that provides a world-class solution for efficiently cleaning cities while conserving resources and maintaining the quality of drain water and landscape. It provides digital tools to government agencies, such as the Cleaning Service departments of cities such as Basel, Geneva, and the Paris region (GPSO). On sweepers and other vehicles traveling through the city cleaning the streets, a camera is coupled to an edge computer unit. Object detection is used to count litter and provide a cleanliness score. This data is shown on a user interface to assist customers in making decisions.
The accuracy of the detection has a significant impact on cleaning resource utilization and management. Precision and recall for distinct classes of litter provide an excellent indicator of quality. The goal of the study was to compare the Cortexia object identification model with a new TensorFlow 2 implementation for transfer learning.
Satanei, Jeremy, and Martin chose and trained various pre-trained models for image detection, thereby transitioning from Tensorflow 1 to Tensorflow 2; they built a ready-to-use data science pipeline that included data formatting and model training; and they evaluated the models using visual checks and common metrics like mean average precision.
They have roughly 10K photos with 200K metadata, indicating 61 litter categories in all. The MobileNet V2 model produced the greatest results since it is light and efficient enough for this type of data. The model was discovered to perform better on medium/large sized objects.

However, to reach a commercially useful level, far more processing power and a much higher number of training rounds are required. The model will also be trained with class balance, data augmentation, freezing approaches, and learning curve monitoring in the future.
Cortexia is a technology firm that provides a world-class solution for efficiently cleaning cities while conserving resources and maintaining the quality of drain water and landscape. It provides digital tools to government agencies, such as the Cleaning Service departments of cities such as Basel, Geneva, and the Paris region (GPSO). On sweepers and other vehicles traveling through the city cleaning the streets, a camera is coupled to an edge computer unit. Object detection is used to count litter and provide a cleanliness score. This data is shown on a user interface to assist customers in making decisions.
The accuracy of the detection has a significant impact on cleaning resource utilization and management. Precision and recall for distinct classes of litter provide an excellent indicator of quality. The goal of the study was to compare the Cortexia object identification model with a new TensorFlow 2 implementation for transfer learning.
Satanei, Jeremy, and Martin chose and trained various pre-trained models for image detection, thereby transitioning from Tensorflow 1 to Tensorflow 2; they built a ready-to-use data science pipeline that included data formatting and model training; and they evaluated the models using visual checks and common metrics like mean average precision.
They have roughly 10K photos with 200K metadata, indicating 61 litter categories in all. The MobileNet V2 model produced the greatest results since it is light and efficient enough for this type of data. The model was discovered to perform better on medium/large sized objects.
However, to reach a commercially useful level, far more processing power and a much higher number of training rounds are required. The model will also be trained with class balance, data augmentation, freezing approaches, and learning curve monitoring in the future.
NxGen Medical Services: Swiss Hospitals Assistant
Students: Zuzana Dostalova and Ansam Zedan
NXGEN Medical Services is a healthcare-focused startup that specializes in data collection, Machine Learning, and predictive analysis.
The goal of this project was to develop an application that could assess patient and disease distribution in certain cantons in order to assist Swiss hospitals in improving treatment options.
Three critical processes were incorporated in the workflow: gathering real-world data from multiple sources, analyzing it, and uploading it to the company database. The team employed Deep Learning to translate the data into English because it includes information in German, French, and Italian. The next stage was to build a pipeline employing text processing techniques so that future data could be easily inserted into the company database.
They also used statistical techniques, visualization, and Machine Learning to analyze the data. These capabilities were crucial to Zuzana and Ansam's interactive app, which they designed with Streamlit.
The graph below, for example, shows the number of patients per hospital by disease category, the city, and canton where the hospital is located, and the population. In the app, you can hover over cities to see more information:

We hope that in the future, this knowledge will assist people in locating the best and most convenient medical facility to treat their sickness. It could also aid in the development of an algorithm to analyze and rate hospital quality based on mortality, patient transfers to another hospital due to a lack of specialized doctors or equipment, duration of stay, and other factors.
We hope that by using this software, we can improve the quality of medical care, particularly in rural areas, and expand the availability of medical equipment.
NXGEN Medical Services is a healthcare-focused startup that specializes in data collection, Machine Learning, and predictive analysis.
The goal of this project was to develop an application that could assess patient and disease distribution in certain cantons in order to assist Swiss hospitals in improving treatment options.
Three critical processes were incorporated in the workflow: gathering real-world data from multiple sources, analyzing it, and uploading it to the company database. The team employed Deep Learning to translate the data into English because it includes information in German, French, and Italian. The next stage was to build a pipeline employing text processing techniques so that future data could be easily inserted into the company database.
They also used statistical techniques, visualization, and Machine Learning to analyze the data. These capabilities were crucial to Zuzana and Ansam's interactive app, which they designed with Streamlit.
The graph below, for example, shows the number of patients per hospital by disease category, the city, and canton where the hospital is located, and the population. In the app, you can hover over cities to see more information:
We hope that in the future, this knowledge will assist people in locating the best and most convenient medical facility to treat their sickness. It could also aid in the development of an algorithm to analyze and rate hospital quality based on mortality, patient transfers to another hospital due to a lack of specialized doctors or equipment, duration of stay, and other factors.
We hope that by using this software, we can improve the quality of medical care, particularly in rural areas, and expand the availability of medical equipment.
Nispera: AI-based Wind Turbine Anomaly Detection
Students: Franco Pallitto and David Peculić
In the last 10 years, particularly after the Paris Agreement, much attention has been placed on mitigating climate change and environmental destruction. One solution to this perplexing situation is to fully abandon fossil fuels in favor of renewable energy sources.
Nispera, a Zürich-based startup launched in 2015, is a fast-growing data solutions provider for the renewable energy market. Their clients have found their data-driven insights and solutions to be quite useful in optimizing energy production.
Nispera works with all important renewable energy sources, but for this project, we concentrated on wind power and wind turbine performance optimization.
The project's goal was to detect and analyze wind turbine anomalies in order to prevent inefficient wind turbine operating. Power Curve Shifts and Power Curtailments were the two anomalies the team was looking for. The Power Curve Shift anomaly is significant because it answers the question of whether the wind turbine has been incorrectly calibrated or whether there are any manufacturing flaws, whereas the Power Curtailment anomaly is significant since it is critical in analyzing power generation over time.

The detection of power curtailments can be seen above, while the detection of power curve alterations can be shown below:

Franco and David used Statistical Approaches and Machine Learning approaches to come up with a solution that can clearly distinguish between the two wind turbine anomalies previously stated.
Finally, the system has the potential to save clients a significant amount of money by detecting and categorizing costly wind turbine faults.
In the last 10 years, particularly after the Paris Agreement, much attention has been placed on mitigating climate change and environmental destruction. One solution to this perplexing situation is to fully abandon fossil fuels in favor of renewable energy sources.
Nispera, a Zürich-based startup launched in 2015, is a fast-growing data solutions provider for the renewable energy market. Their clients have found their data-driven insights and solutions to be quite useful in optimizing energy production.
Nispera works with all important renewable energy sources, but for this project, we concentrated on wind power and wind turbine performance optimization.
The project's goal was to detect and analyze wind turbine anomalies in order to prevent inefficient wind turbine operating. Power Curve Shifts and Power Curtailments were the two anomalies the team was looking for. The Power Curve Shift anomaly is significant because it answers the question of whether the wind turbine has been incorrectly calibrated or whether there are any manufacturing flaws, whereas the Power Curtailment anomaly is significant since it is critical in analyzing power generation over time.
The detection of power curtailments can be seen above, while the detection of power curve alterations can be shown below:
Franco and David used Statistical Approaches and Machine Learning approaches to come up with a solution that can clearly distinguish between the two wind turbine anomalies previously stated.
Finally, the system has the potential to save clients a significant amount of money by detecting and categorizing costly wind turbine faults.
South Pole: Super resolution for Satellite Imagery
Students: Elena Gronskaya and Özgün Haznedar
South Pole is a global company that works with businesses and governments to achieve carbon reduction, climate action, and sustainability programs. One of the concerns being addressed is deforestation, which diminishes the capacity for carbon sequestration in ecosystems all around the world.
South Pole needs to use satellite imagery to compare the amount of carbon sequestered in a given geographical region before and after interventions, such as the creation of protected national parks/safari reserves, the introduction of effective farming techniques to the community, and so on, in order to assess the impact of these interventions (usually a period of 7-10 years). Because high-resolution satellite imagery has been unavailable for many years and only medium-resolution photos are available for the historical baseline period, producing sufficiently precise assessments for the historical baseline is typically challenging, resulting in a lot of human labor.
Elena and zgün used Deep Learning models for Image Super-Resolution to solve this problem, which involved training a convolutional neural network to downscale medium-resolution satellite photos to make them equivalent to high-resolution images.
They acquired photos from Lansdat 8 (30 m/pixel resolution) and Sentinel-2 (10 m/pixel resolution) using the python API for Google Earth Engine. The places were picked from areas with high rates of deforestation. A dataset of 800 quality picture pairings was obtained after filtering away cloudy and defective images and temporally matching the Landsat-Sentinel pairs to be shot within a maximum of 7 days of each other.

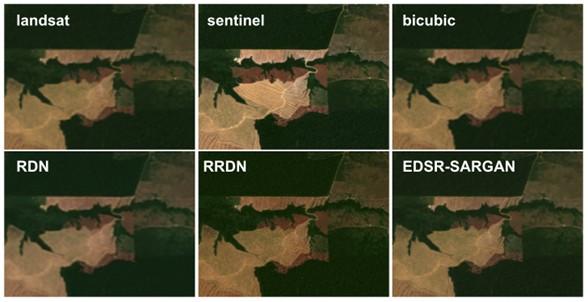
Residual Dense Network (RDN), Residual in Residual Dense Network (RRDN1, RRDN2), EDSR, and Super Resolution GAN are some of the networks that have been implemented (SRGAN1, SRGAN2).
The team generated super-resolution images that outperformed the benchmark images after training their models using the gold-standard DIV2K dataset as well as their own Landsat-Sentinel satellite image pair data, evaluating multiple hyperparameters, and fine-tuning.
The best-looking results came from models with adversarial components (RRDN and SRGAN EDSR). The models' predictions were assessed using a gradient-based sharpness index.

Finally, they built a proof-of-concept for upgrading low-resolution satellite photos using Deep Learning-based Image Super-Resolution models. The images that result could help measure the impact of interventions on carbon sequestration in the areas where climate action projects have been implemented.
Future plans involve using more data from different regions to train these models and experimenting with newer Super-Resolution model architectures driven by Transformers.
Thank you everybody for a fantastic partnership and an amazing project period! We at Constructor Academy wish our Data Science graduates the best of luck.
South Pole is a global company that works with businesses and governments to achieve carbon reduction, climate action, and sustainability programs. One of the concerns being addressed is deforestation, which diminishes the capacity for carbon sequestration in ecosystems all around the world.
South Pole needs to use satellite imagery to compare the amount of carbon sequestered in a given geographical region before and after interventions, such as the creation of protected national parks/safari reserves, the introduction of effective farming techniques to the community, and so on, in order to assess the impact of these interventions (usually a period of 7-10 years). Because high-resolution satellite imagery has been unavailable for many years and only medium-resolution photos are available for the historical baseline period, producing sufficiently precise assessments for the historical baseline is typically challenging, resulting in a lot of human labor.
Elena and zgün used Deep Learning models for Image Super-Resolution to solve this problem, which involved training a convolutional neural network to downscale medium-resolution satellite photos to make them equivalent to high-resolution images.
They acquired photos from Lansdat 8 (30 m/pixel resolution) and Sentinel-2 (10 m/pixel resolution) using the python API for Google Earth Engine. The places were picked from areas with high rates of deforestation. A dataset of 800 quality picture pairings was obtained after filtering away cloudy and defective images and temporally matching the Landsat-Sentinel pairs to be shot within a maximum of 7 days of each other.
Residual Dense Network (RDN), Residual in Residual Dense Network (RRDN1, RRDN2), EDSR, and Super Resolution GAN are some of the networks that have been implemented (SRGAN1, SRGAN2).
The team generated super-resolution images that outperformed the benchmark images after training their models using the gold-standard DIV2K dataset as well as their own Landsat-Sentinel satellite image pair data, evaluating multiple hyperparameters, and fine-tuning.
The best-looking results came from models with adversarial components (RRDN and SRGAN EDSR). The models' predictions were assessed using a gradient-based sharpness index.
Finally, they built a proof-of-concept for upgrading low-resolution satellite photos using Deep Learning-based Image Super-Resolution models. The images that result could help measure the impact of interventions on carbon sequestration in the areas where climate action projects have been implemented.
Future plans involve using more data from different regions to train these models and experimenting with newer Super-Resolution model architectures driven by Transformers.
Thank you everybody for a fantastic partnership and an amazing project period! We at Constructor Academy wish our Data Science graduates the best of luck.
